Ian Jackson: partial-borrow: references to restricted views of a Rust struct
tl;dr:
With these two crazy proc-macros you can hand out multipe (perhaps mutable) references to suitable subsets/views of the same struct. Why In Otter I have adopted a style where I try to avoid giving code mutable access that doesn't need it, and try to make mutable access come with some code structures to prevent "oh I forgot a thing" type mistakes. For example, mutable access to a game state is only available in contexts that have to return a value for the updates to send to the players. This makes it harder to forget to send the update. But there is a downside. The game state is inside another struct, an
 comments
comments
With these two crazy proc-macros you can hand out multipe (perhaps mutable) references to suitable subsets/views of the same struct. Why In Otter I have adopted a style where I try to avoid giving code mutable access that doesn't need it, and try to make mutable access come with some code structures to prevent "oh I forgot a thing" type mistakes. For example, mutable access to a game state is only available in contexts that have to return a value for the updates to send to the players. This makes it harder to forget to send the update. But there is a downside. The game state is inside another struct, an
Instance, and much code needs (immutable) access to it. I can't pass both &Instance and &mut GameState because one is inside the other.
My workaround involves passing separate references to the other fields of Instance, leading to some functions taking far too many arguments. 14 in one case. (They're all different types so argument ordering mistakes just result in compiler errors talking about arguments 9 and 11 having wrong types, rather than actual bugs.)
I felt this problem was purely a restriction arising from limitations of the borrow checker. I thought it might be possible to improve on it. Weeks passed and the question gradually wormed its way into my consciousness. Eventually, I tried some experiments. Encouraged, I persisted.
What and how
partial-borrow is a Rust library which solves this problem. You sprinkle #[Derive(PartialBorrow)] and
partial!(...) and then you can
pass a reference which grants mutable access to only some of the fields. You can also pass a reference through which some fields are inaccessible. You can even split a single mut reference into multiple compatible references, for example granting mut access to mutually-nonverlapping subsets.
The core type is Struct__Partial (for some Struct).
It is a zero-sized type, but we prevent anyone from constructing one.
Instead we magic up references to it, always ensuring that they have the same address as some Struct.
The fields of Struct__Partial are also ZSTs that exist ony as references, and they Deref to the actual field (subject to compile-type borrow compatibility checking).
Soundness and testing
partial-borrow is primarily a nontrivial procedural macro which autogenerates reams of unsafe.
Of course I think it's sound, but I thought that the last two times before I added a test which demonstrated otherwise. So it might be fairer to say that I have tried to make it sound and that I don't know of any problems...
Reasoning about the correctness of macro-generated code is not so easy. One problem is that there is nowhere good to put the kind of soundness arguments you would normally add near uses of unsafe.
I decided to solve this by annotating an instance of the macro output. There's a not very complicated script using diff3 to help fold in changes if the macro output changes - merge conflicts there mean a possible re-review of the argument text. Of course I also have test cases that run with miri, and test cases for expected compiler errors for uses that need to be forbidden for soundness.
But this is quite hairy and I'm worried that it might be rather "my first insane unsafe contraption".
Also the pointer/reference trickery is definitely subtle, and depends heavily on knowing what Rust's aliasing and pointer provenance rules really are. Stacked Borrows is not entirely trivial to reason about in fiddly corner cases.
So for now I have only called it 0.1.0 and left a note in the docs. I haven't actually made Otter use it yet but that's the rather more boring software integration part, not the fun "can I do this mad thing" part so I will probably leave that for a rainy day. Possibly a rainy day after someone other than me has looked at partial-borrow (preferably someone who understands Stacked Borrows...).
Fun!
This was great fun. I even enjoyed writing the docs.
The proc-macro programming environment is not entirely straightforward and there are a number of things to watch out for. For my first non-adhoc proc-macro this was, perhaps, ambitious. But you don't learn anything without trying...
edited 2021-09-02 16:28 UTC to fix a typo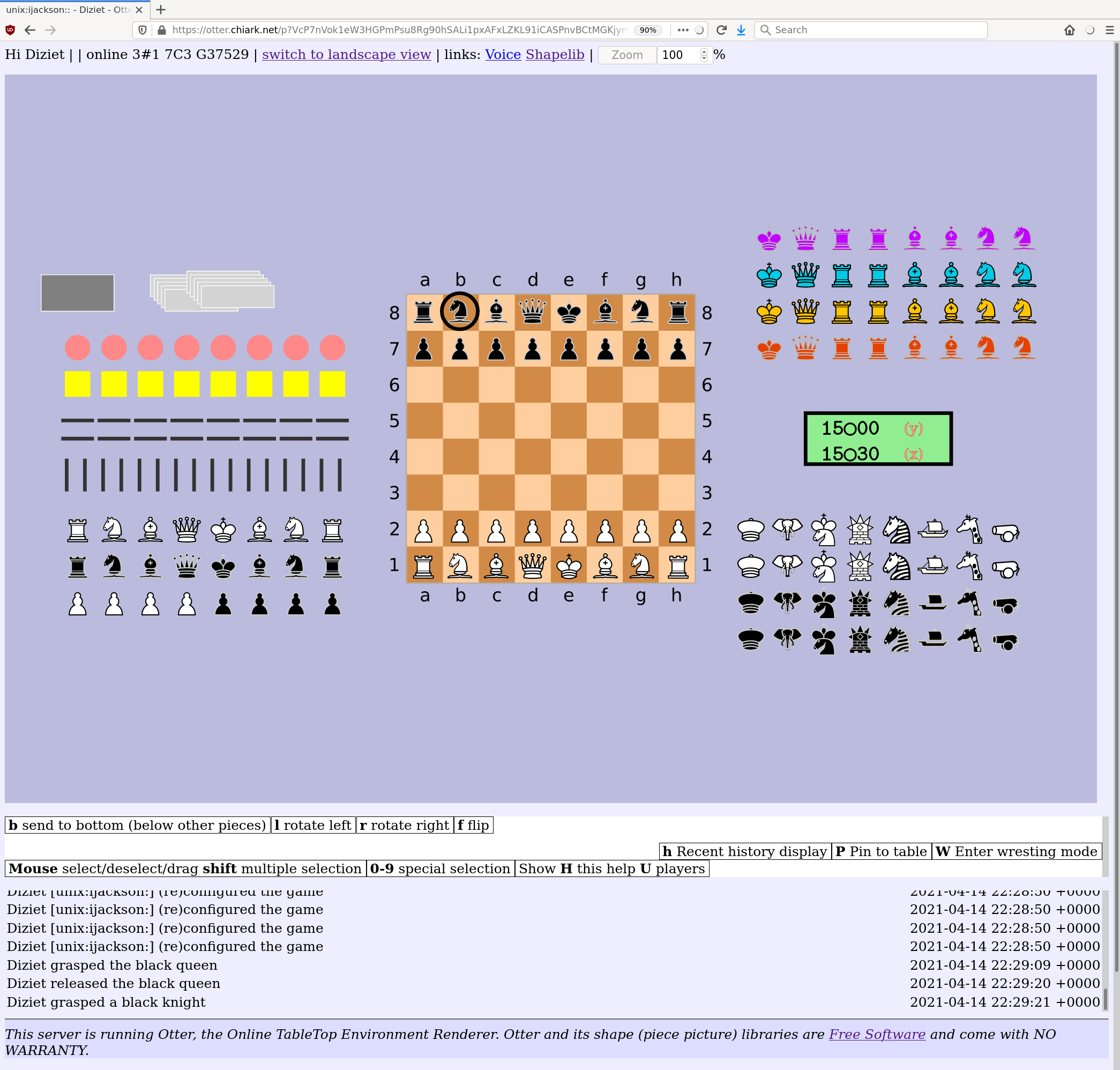
 Scaffolding is fairly expensive but building things out of it is enormous fun! You can see a complete sequence of the build process, including pictures of the "engineering maquette", at
Scaffolding is fairly expensive but building things out of it is enormous fun! You can see a complete sequence of the build process, including pictures of the "engineering maquette", at  DebConf4
This tshirt is 16 years old and from DebConf4. Again, I should probably wash it at 60 celcius for once...
DebConf4
This tshirt is 16 years old and from DebConf4. Again, I should probably wash it at 60 celcius for once...

 Finally, DebConf4 and more importantly FISL, which was really big (5000 people?) and after that,
the
Finally, DebConf4 and more importantly FISL, which was really big (5000 people?) and after that,
the 


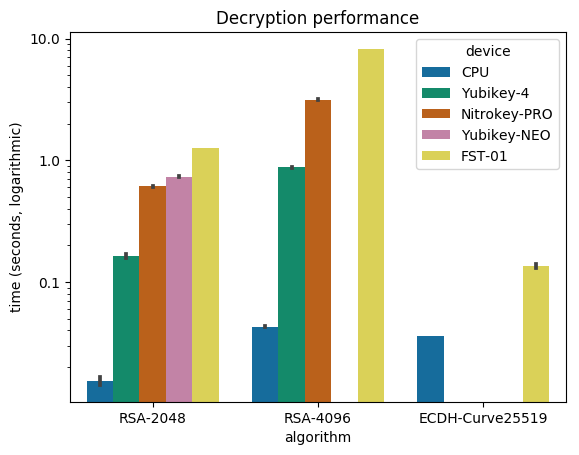

 I was recently asked to sort things out so that
I was recently asked to sort things out so that